时间:2023-05-11 15:24:41 点击次数:8
入坑深度学习已快两年,读过不少论文,也复现过不少代码,包括常用的骨干网、注意力机制、数据增强、网络正则化、特征可视化、各种GAN、各种Loss函数。因为代码这块一直都是自己摸索着前行,走了不少弯路,甚至现在,也偶尔会发现一些自己一直忽略的细节。因此最近把代码重新整理了一番,觉得用起来还比较方便,顺便就把它分享出来了。
原文链接:【Pytorch源码模板】深度学习代码:各种骨干网、注意力、Loss、可视化、增强(十万行代码整理,超强模板,入门即精通不是梦)
源码模板主要由以下几个模块构成,依次是:特征可视化、数据增强和网络正则化、数据集和加载、模型部署、各种常用深度学习模型、各种常用Loss、模型保存和tensorbord可视化、tf模型转pytorch,以及模型的训练和测试。

大多都有详细的方法介绍和使用说明:

我个人不太喜欢命令行编辑,所以源码已将大部分超参封装到了args.py文件:
import os class data_config: model_name = "baseline" ***********- dataset and directory-************* dataset=cifar100 input_size = 32 num_class = 100 data_path = /disks/disk2/lishengyan/MyProject/Attention_and_CifarModel/dataset train_file= val_file = test_file = MODEL_PATH = /disks/disk2/lishengyan/MyProject/Attention_and_CifarModel/ckpts/cifar100/resnet50/esebase_fselectmixno/ if not os.path.exists(MODEL_PATH): os.makedirs(MODEL_PATH) ***********- Hyper Arguments-************* autoaug = 0 # Auto enhancement set to 1 gpus=[0,1] #[1,2,3] WORKERS = 5 tensorboard= False epochs = 200 batch_size = 128 delta =0.00001 rand_seed=40 #Fixed seed greater than 0 lr=0.1 warm=1#warm up training phase optimizer = "torch.optim.SGD" optimizer_parm = {lr: lr,momentum:0.9, weight_decay:5e-4, nesterov:False} # optimizer = "torch.optim.AdamW" # optimizer_parm = {lr: 0.001, weight_decay: 0.00001} #学习率:小的学习率收敛慢,但能将loss值降到更低。当使用平方和误差作为成本函数时,随着数据量的增多,学习率应该被设置为相应更小的值。adam一般0.001,sgd0.1,batchsize增大,学习率一般也要增大根号n倍 #weight_decay:通常1e-4——1e-5,值越大表示正则化越强。数据集大、复杂,模型简单,调小;数据集小模型越复杂,调大。 loss_f =torch.nn.CrossEntropyLoss loss_dv = torch.nn.KLDivLoss loss_fn = torch.nn.BCELoss # loss_fn = torch.nn.BCEWithLogitsLoss # loss_fn=torch.nn.MSELoss fn_weight =[3.734438666137167, 1.0, 1.0, 1.0, 3.5203138607843196, 3.664049338245769, 3.734438666137167, 3.6917943287286734, 1.0, 3.7058695139403963, 1.0, 2.193419513003608, 3.720083373160097, 3.6917943287286734, 3.734438666137167, 1.0, 2.6778551377707998]train_baseline.py是启动训练和测试的主文件,只需在args.py修改参数配置即可。
***********- trainer -************* class trainer: def __init__(self, loss_f,loss_dv,loss_fn, model, optimizer, scheduler, config): self.loss_f = loss_f self.loss_dv = loss_dv self.loss_fn = loss_fn self.model = model self.optimizer = optimizer self.scheduler = scheduler self.config = config def batch_train(self, batch_imgs, batch_labels, epoch): predicted = self.model(batch_imgs) loss =self.myloss(predicted, batch_labels) predicted = softmax(predicted, dim=-1) del batch_imgs, batch_labels return loss, predicted def train_epoch(self, loader,warmup_scheduler,epoch): self.model.train() tqdm_loader = tqdm(loader) losses = AverageMeter() top1 = AverageMeter() top5 = AverageMeter() print("\n************Training*************") for batch_idx, (imgs, labels) in enumerate(tqdm_loader): # print("data",imgs.size(), labels.size())#[128, 3, 32, 32]) torch.Size([128] if (len(data_config.gpus) > 0): imgs, labels=imgs.cuda(), labels.cuda() # print(self.optimizer.param_groups[0][lr]) loss, predicted = self.batch_train(imgs, labels, epoch) losses.update(loss.item(), imgs.size(0)) # print(predicted.size(),labels.size()) self.optimizer.zero_grad() loss.backward() self.optimizer.step() # self.scheduler.step() err1, err5 = accuracy(predicted.data, labels, topk=(1, 5)) top1.update(err1.item(), imgs.size(0)) top5.update(err5.item(), imgs.size(0)) tqdm_loader.set_description(Training: loss:{:.4}/{:.4} lr:{:.4} err1:{:.4} err5:{:.4}. format(loss, losses.avg, self.optimizer.param_groups[0][lr],top1.avg, top5.avg)) if epoch <= data_config.warm: warmup_scheduler.step() # if batch_idx%1==0: # break return top1.avg, top5.avg, losses.avg def valid_epoch(self, loader, epoch): self.model.eval() # tqdm_loader = tqdm(loader) losses = AverageMeter() top1 = AverageMeter() top5 = AverageMeter() print("\n************Evaluation*************") for batch_idx, (batch_imgs, batch_labels) in enumerate(loader): with torch.no_grad(): if (len(data_config.gpus) > 0): batch_imgs, batch_labels = batch_imgs.cuda(), batch_labels.cuda() predicted= self.model(batch_imgs) loss = self.myloss(predicted, batch_labels).detach().cpu().numpy() predicted = softmax(predicted, dim=-1) losses.update(loss.item(), batch_imgs.size(0)) err1, err5 = accuracy(predicted.data, batch_labels, topk=(1, 5)) top1.update(err1.item(), batch_imgs.size(0)) top5.update(err5.item(), batch_imgs.size(0)) return top1.avg, top5.avg, losses.avg def myloss(self,predicted,labels): # print(predicted.size(),labels.size())#[128, 10]) torch.Size([128]) loss = self.loss_f(predicted,labels) return loss def run(self, train_loder, val_loder,model_path): best_err1, best_err5 = 100,100 start_epoch=0 top_score = np.ones([5, 3], dtype=float)*100 top_score5 = np.ones(5, dtype=float) * 100 iter_per_epoch = len(train_loder) warmup_scheduler = WarmUpLR(optimizer, iter_per_epoch * data_config.warm) # model, optimizer, start_epoch=load_checkpoint(self.model,self.optimizer,model_path) for e in range(self.config.epochs): e=e+start_epoch+1 print("------model:{}----Epoch: {}--------".format(self.config.model_name,e)) if e > data_config.warm: self.scheduler.step(e) # adjust_learning_rate(self.optimizer,e,data_config.model_type) # torch.cuda.empty_cache() _, _, train_loss = self.train_epoch(train_loder,warmup_scheduler,e) err1, err5, val_loss=self.valid_epoch(val_loder,e) # print("\nval_loss:{:.4f} | err1:{:.4f} | err5:{:.4f}".format(val_loss, err1, err5)) if(data_config.tensorboard): writer.add_scalar(training loss, train_loss, e) writer.add_scalar(valing loss, val_loss, e) writer.add_scalar(err1, err1, e) writer.add_scalar(err5, err5, e) writer.close() print(\nbest score:{}.format(data_config.model_name)) print(Best(top-1 and 5 error):,top_score[:, 1].mean(), best_err1, best_err5) print("best accuracy:\n avg_acc1:{:.4f} | best_acc1:{:.4f} | avg_acc5:{:.4f} | | best_acc5:{:.4f} ". format(100 - top_score[:, 2].mean(), 100 - best_err1, 100 - top_score5.mean(), 100 - best_err5))完整而又简洁的实时显示界面:

方法综述:【万字总结】数据增强、网络正则化方法总结:cutmix、cutout、shakedrop、mixup等(附代码)
包含大量数据增强和网络正则化方法以及测试结果:
- StochDepth - label smoothing - Cutout - DropBlock - Mixup - Manifold Mixup - ShakeDrop - cutmix
综述解读:
落尽花去却回:图像处理注意力机制Attention汇总(附代码)
- **SE Attention** - **External Attention** - **Self Attention** - **SK Attention** - **CBAM Attention** - **BAM Attention** - **ECA Attention** - **DANet Attention** - **Pyramid Split Attention(PSA)** - **EMSA Attention** - **A2Attention** - **Non-Local Attention** - **CoAtNet** - **CoordAttention** - **HaloAttention** - **MobileViTAttention** - **MUSEAttention** - **OutlookAttention** - **ParNetAttention** - **ParallelPolarizedSelfAttention** - **residual_attention** - **S2Attention** - **SpatialGroupEnhance Attention** - **ShuffleAttention** - **GFNet Attention** - **TripletAttention** - **UFOAttention** - **VIPAttention**综述解读:【嵌入式AI部署&基础网络篇】轻量化神经网络精述--MobileNet V1-3、ShuffleNet V1-2、NasNet
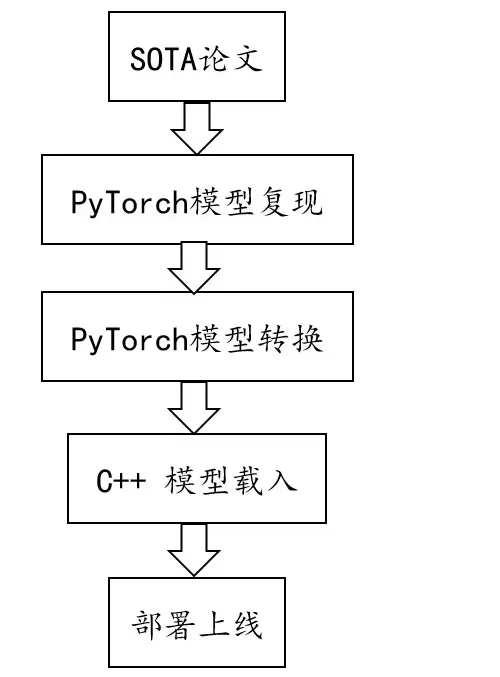
- **MobileNets:** - **MobileNetV2:** - **MobileNetV3:** - **ShuffleNet:** - **ShuffleNet V2:** - **SqueezeNet** - **Xception** - **MixNet** - **GhostNet**提供两种pytorch模型的部署方式,一种为web部署,一种是c++部署;
业界与学术界最大的区别在于工业界的模型需要落地部署,学界更多的是关心模型的精度要求,而不太在意模型的部署性能。一般来说,我们用深度学习框架训练出一个模型之后,使用Python就足以实现一个简单的推理演示了。但在生产环境下,Python的可移植性和速度性能远不如C++。所以对于深度学习算法工程师而言,Python通常用来做idea的快速实现以及模型训练,而用C++作为模型的生产工具。目前PyTorch能够完美的将二者结合在一起。实现PyTorch模型部署的核心技术组件就是TorchScript和libtorch。
综述解读:图像处理特征可视化方法总结(特征图、卷积核、类可视化CAM)
- CAM - ScoreCAM - SSCAM - ISCAM - GradCAM - Grad-CAM++ - Smooth Grad-CAM++ - XGradCAM - LayerCAM公众号"AI研修 潜水摸大鱼”回复“torch源码”获取完整代码,或评论区。持续更新各类深度学习前缘技术的综述性解读,更有涵盖CV,NLP,嵌入式AI,C++/JAVA开发的各类最新资讯。





