时间:2023-07-03 22:18:19 点击次数:21
在业内由于某些不可抗力的因素,我们不得不去做一些麻烦的事情来备份资料。为了尽最大可能挽留那些知识,也就有了这篇文章和最后的脚本。(文章和脚本写的都异常粗糙,希望师傅们不要介意。)
关于网站复制:
网站复制,也可称为网站备份。是通过工具将网页上的内容全部保存下来。当然不仅仅只是保存了一个html页面,而是将网页源码内所包含的css、js和静态文件等全部保存,以在本地也可以完整的浏览整个网站。网络上也有一些类似的工具,但使用起来并不理想。于是我打算自己写一个Python脚本,方便个人对网站的备份,也方便一些网络资料的收集。
在开始动手写代码之前,我们需要确定一下要保存下来的内容,以便后期编写脚本来处理。
暂且分为这么两个部分:
网页源码(单个页面的html源码)css、js与图片文件(静态文件)css、js与图片文件的下载地址都是从网页源码中获取得到的,如图:
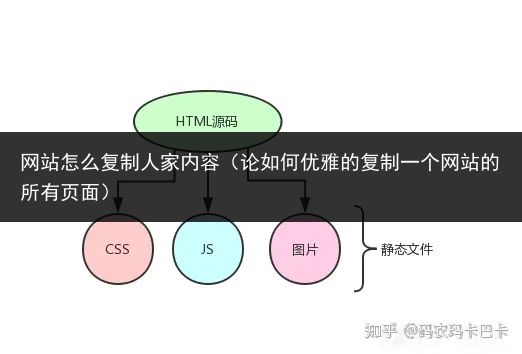
内容似乎不是很多,就只需要把静态文件的下载地址从网页源码中提取出来然后下载保存就行了。但是实际情况会比较麻烦,为什么呢?
下图是一个静态文件的保存过程,文件在下载保存之前还需要处理相对地址进而得到文件的下载地址以及保存到本地的路径。除此之外,还要对HTML源码中原来的相对地址进行替换,让文件内容在本地也能够正常的使用并显示。这也是保存网页相对来说复杂的地方,在获取链接之后我们来看看如何处理这个情况。

有了一个页面的链接,就可以通过这个链接获取HTML源码进而获取各类文件的相对地址。相较于路径处理,这里的方式就简单直接很多。用beautifulsoup直接获取标签,再获取链接即可。过程如图:
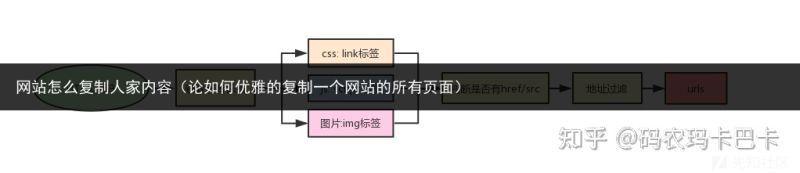
通过构造一个ExtractLinks()函数来获取一个网页内所有同类标签的同种参数。可以节省一些重复的语句,方面获取到css、js、img、a标签的url地址。
这里的过滤的内容如下:
去重复丢弃无效url地址如:#、javascript伪协议等那获取了链接之后就需要对路径进行处理了。
在网页源码当中,相对地址的形式有很多种情况。
需要正常应对的相对地址形式有多少种呢?用图片文件作为一个例子,简单总结了一些如下:

(在确定的形式之外又会有很多种我们不能预测的情况。对于那些不确定的地址,就直接作丢弃处理。)
从相对地址的类型也能看出来,要写处理的代码的话会有很多不同的情况,每种情况基本都需要进行单独的处理,并且其中的逻辑也是稍微有点绕。
这里我们建立一个ProcessResourcePath的函数来处理文件相对地址的关系
处理链接时需要的传入参数:
页面地址:用于获取源码中的文件地址,并根据url的层级关系确定图片保存的路径。图片地址:根据页面地址与图片地址确定图片的下载地址返回的参数:
页面地址图片地址图片的下载地址替换的图片地址保存的路径图片地址的类型(方便DEBUG)函数处理的过程如图:
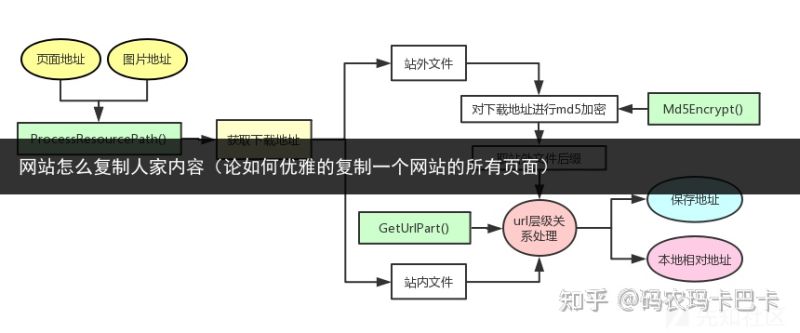
函数解释:
Md5Encrypt(): 是用作对站外文件的下载链接进行MD5加密,防止重复下载GetUrlPart(): 用于获取url中不同部分的值,方便对url的处理ProcessResourcePath(): 处理页面地址和图片地址的相对关系URL层级关系的处理就不解释了,比较麻烦。如果有对单个过程感兴趣可以直接跟我交流喔。通过这个函数的处理之后,保存网页时就变得非常方便。因为你只需要将css、js、图片等文件的链接提取出来进行处理,将处理完的地址进行替换即可。
那在保存单个页面之前,需要往前思考一点。最终的文件都是要保存到一个总文件夹里,这个文件夹的名字得提前确定。我这里想把一个网站保存到以域名为名称的文件夹中,比如 http://www.bilibili.com 的所有页面和资源就全部保存到www_bilibili_com的文件夹里。所以,保存单个页面所需要的参数就为页面的地址,再通过页面的地址获取域名来定义保存的文件夹。保存的时候需要将页面html源码中的地址进行替换。
文件地址替换文件和页面都直接保存下来了,该怎么让页面可以正常调用本地的js和显示本地的图片呢?我们需要做的就是将页面中的文件地址都进行替换。配合之前的网址处理函数,将页面地址和文件地址通过ProcessResourcePath处理后得到适配本地的地址,然后进行替换即可。
链接地址替换不止是css、js、图片文件需要处理好相对位置,单个页面也需要处理里面的各个链接。这样在本地就可以在各个页面正常切换。因为在服务器上的页面是动态生成的,我们把网页保存下来后,都应该修改为.html结尾的文件,于是就有这几种情况:
以.html结尾的 => 直接以原文件名保存以.php等不适.html结尾的 => 在原来的文件名后添加.html后缀保存没有文件名的 => 保存为index.html在保存单个页面的时候进行一次这样的处理,在链接地址替换的时候对a标签内的地址也进行一次这样的处理就可以保证各个页面的地址之间的正常交互了。(对链接的处理仅限于同一个子域名)
保存并处理一个网页,就是要保证css、js、图片文件能够正常调用与显示。并且链接能够与多个页面进行交互。
通过前面的内容,已经可以获取到单个页面的所有内容,并且可以较好的处理里面的链接关系。那该怎么获取得到整个网站的所有页面呢?非常的简单粗暴,就是遍历所有链接!(也没想到其他好的方式了)遍历网页url流程图:

通过这个方式把网站所有的url获取到,然后批量进行单个页面的保存即可。
为了加快获取网站所有页面的链接和保存每个页面的文件,我们需要使用多线程和协程来加快执行效率。
我使用的是自己写的一个简单的协程框架:
协程初体验之简单的利用框架
这个框架的流程如下图所示:
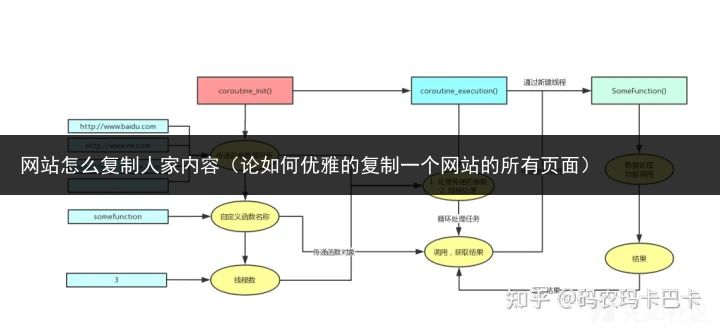
框架写的比较简陋,修改一下是可以直接用到复制网站脚本里面的。具体内容可以进文章里面细看。
通过协程,可以显著加快获取网站所有页面与保存单个页面的速度。
文章中各个部分的代码实现都在一个python脚本当中,github仓库地址如下:
SiteCopy: https://github.com/Threezh1/SiteCopy
使用命令:复制单个页面:
python sitecopy.py -u "https://threezh1.com"
复制整个网站(-t设置线程):
python sitecopy.py -u "https://threezh1.com" -e -t 30
声明:
对互联网任何网站的复制需在取得授权后方可进行,若使用者因此做出危害网络安全的行为后果自负,与作者无关,特此声明。
非常希望能够和师傅们共同交流对这些问题的解决方式,我的邮箱:makefoxm@qq.com
运行截图:
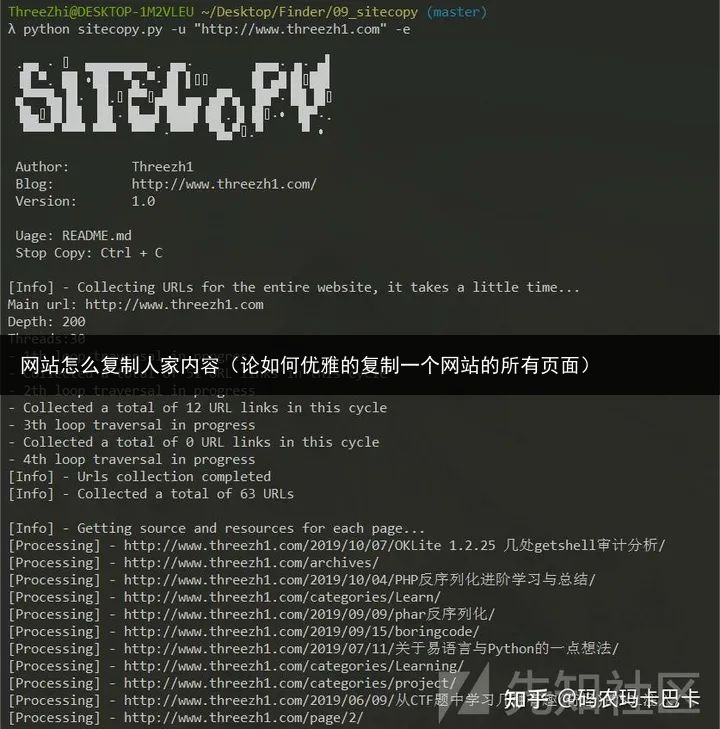
目录截图:

页面截图:
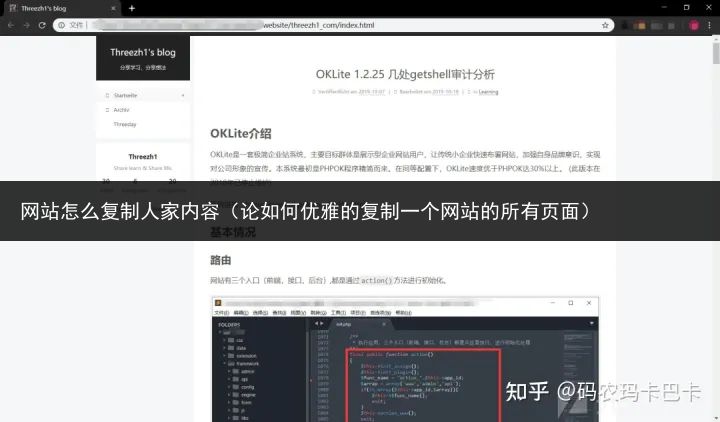 本文转自先知社区,原作者Threezh1(侵删)
本文转自先知社区,原作者Threezh1(侵删)推荐阅读:
事发突然,我中了勒索病毒!破解Wif密码最简单的步骤,仅需三步常用红队安全攻防总结关注【网络安全资源库】,学习更多网络安全干货,还可获得超多资料哦~





